In artificial neural networks (NNs), each neuron corresponds to a single scalar value. Now imagine that a neuron is represented by a signal which over time converges (in a meaningful way) to the same value. Indeed, what if there was a chemical network tightly connected to a neural network, in a sense that its chemical signals (molecular concentrations) correspond to values of the neurons.
Indeed, in this article I will tell you about a tight connection between neural and chemical reaction networks (CRNs). This connection brings an interesting property: values of all neurons within a neural network are associated with chemical signals which values change over time and furthermore they converge to the exact same values as the neural network produces. While this insight is useful in molecular programming community (our initial motivation), there is another interesting aspect of it: Can we gain any insights about the behavior of a neural net by observing patterns that associated chemical signals exhibit in time domain? Does longer convergence time of chemicals imply that the network is less confident in its output, does oscillating pattern of signals inform if neural network is overfitting, can we better inform our neural network training by looking at the chemical signals? Those and many other questions open up in my mind when I think about the connection between these two worlds. I hope this article will encourage other research minded people to explore the possibilities.
Analogies between chemistry and other areas have been detected; furthermore benefits of such analogy for better understanding the other area have been envisioned. For example, in the work of Leonard Adleman, Turing Award winner, he mentions: “we seek to exploit an analogy between number theory and chemistry, where atoms are to molecules as primes are to numbers.”, further on “with an appropriate choice of specific rates of reactions the resulting event-system has the property that the sum of equilibrium concentrations of all species at complex temperature s is the value of the Riemann zeta function at s. We hope to pursue this approach to study questions related to the distribution of the primes.” Overall, Adleman planned to utilize analogy with chemistry to help study questions related to the distribution of the primes. This article brings a similar point, but analogy is between chemistry and neural networks.
Tight Translation Scheme from Chemical to Neural Networks
In our ICML’20 paper and follow up PNAS’22 paper we present a scheme of translating neural to chemical networks (shown below).

Each component of a neural network: (a) fan-out, (b) weighted sum, (c) ReLU activation function, (d) bias terms; is shown, as well as its chemical counterpart.
The above scheme is particularly efficient for Binary-Weight neural networks, i.e., networks that have weights with values in range {-1, 0, 1}. Binary-Weight networks were popularized in ML community because they provide significant power consumption savings and are shown to achieve good performance (e.g., see BinaryConnect). In chemical world, Binary-Weight networks are efficient in a sense of their implementability in chemical hardware such as DNA. However, aim of this article is not to delve into details of the implementability via DNA nanotechnology (for that check our papers), but to paint a high level picture of the connection between the worlds of artificial neural and chemical networks.
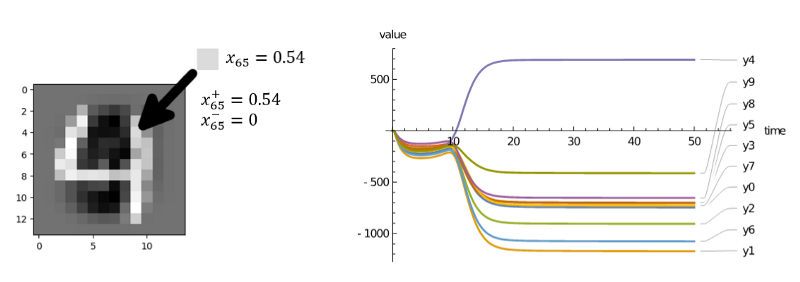
Since we presented the translation scheme from NNs to CRNs, let’s see it in action! The next Figure illustrates results of translating neural network trained on MNIST to a chemical network.
I also include a richer example, with a larger variety of neural networks and its chemical counterparts, for your reference. Hope you enjoy looking at the graphs as much as I did (though spending hours/days preparing the following figure for PNAS I didn’t enjoy too much :)

I will briefly talk about 4A-D part of the figure above. This example is inspired by the problem of spatial pattern formation, which is still an open challenge for the field of synthetic biology. Spatial pattern formation represents a challenge of forming a desired pattern in a given space. In human development, pattern formation ensures that organs and tissues develop correctly. To mimic a pattern formation problem, we construct a network that based on the position in space (coordinates x1 and x2) produces a different response. Thus, inputs of the neural network are coordinates in the system (x1 and x2). Outputs of the neural network represent the color (black or white). In this way neural network can learn the pattern (image) that is of interest. (in principle, x1 and x2 can be implemented in chemistry via chemical gradient, thus enabling the chemical system to construct pattern in space). For the matter of this article, this network is important because of the following example:

In the above figure we show convergence (stabilization) times for different inputs of the pattern formation NN (different inputs correspond to different parts of the image). We show the confidence of the neural network in a correct output for the same inputs. What’s intriguing is that there is a high correlation between the stabilization time of the chemical network and confidence of the neural network in its output. In other words, when the neural network is less confident about its output prediction, it takes longer for the chemical network to converge. (we don’t have a proof that this in general holds, but is an intriguing thought). If such an analogy exists, although not immediately useful, it opens up questions of whether there are other useful analogies. Moreover, whether there are such analogies that certain properties of a neural network are easier to analyze in chemical space.
Why Care About Chemical Counterpart of Neural Networks
Initial motivation of our research and resulting papers is building a powerful programming paradigm for chemical hardware. Our work enables encoding computation with data - training a network on a dataset, and implementing the learned algorithm in chemical hardware (DNA). Our work also has important property of rate-independence, thus one doesn’t have to worry about the hard task of tuning reaction rates when doing DNA implementation.
However, the chemical representation provides a completely new way of analyzing neural networks. There are many open problems in neural network training and analysis, which keep the research going - this article provides a new gadget in a toolbox that might prove useful in some way. The article does not provide ultimate answers of when using chemical paradigm to analyze neural network behavior is going to prove useful, but it hints at possibilities instead.
Threats to Validity
One may ask: Of what use is the chemical representation for analyzing behavior of neural networks. In the end what you did is you developed a method to “simulate” neural networks in chemistry. Previous is a valid comment. While I don’t claim the opposite is true, there are reasons why I think there could be something more to it: (a) Connection between neural and chemical networks we came up with is very tight - one neuron corresponds to one bimolecular reaction (after optimization is performed that I haven’t talked about in the article); (b) We developed a bidirectional connection, where we can translate between both of the worlds, not just in one direction. Due to the previous reasons, “tightness” of the translation scheme, I believe that certain properties of chemical representation map into properties of the associated neural network.
Supplementary Material
Implementation of our translation procedure from Neural Networks to Chemical Reaction Networks can be found on a following GitHub link: https://github.com/marko-vasic/dmp.
I am open to any comments, suggestions, critique, as well as praise. :)